![]()
Analysis of single-cell RNA-seq data: building and annotating an atlas¶
This Python notebook pre-processes the pbmc_1k v3 dataset from 10X Genomics with kallisto and bustools using kb, and then performs an analysis of the cell types and their marker genes.
The notebook was written by A. Sina Booeshaghi and Lior Pachter and is based on three noteboks: - The kallisto | bustools Introduction to single-cell RNA-seq I notebook. - The kallisto | bustools Introduction to single-cell RNA-seq II notebook. - The Scanpy Preprocessing and clustering 3k PBMCs" notebook.
If you use the methods in this notebook for your analysis please cite the following publications which describe the tools used in the notebook:
- Melsted, P., Booeshaghi, A.S. et al. Modular and efficient pre-processing of single-cell RNA-seq. bioRxiv (2019). doi:10.1101/673285
- Wolf, F. A., Angere, P. and Theis, F.J. SCANPY: large-scale single-cell gene expression data analysis. Genome Biology (2018). doi:10.1186/s13059-017-1382-0
An R notebook implementing the same analysis is available here. See the kallistobus.tools tutorials site for additional notebooks demonstrating other analyses.
Setup¶
1 2 3 | |
Install python packages¶
1 2 3 4 5 | |
[K |████████████████████████████████| 1.4MB 4.2MB/s
[K |████████████████████████████████| 3.2MB 34.9MB/s
[K |████████████████████████████████| 2.2MB 4.3MB/s
[K |████████████████████████████████| 2.0MB 36.8MB/s
[K |████████████████████████████████| 81kB 7.9MB/s
[K |████████████████████████████████| 133kB 43.0MB/s
[K |████████████████████████████████| 71kB 7.5MB/s
[K |████████████████████████████████| 1.1MB 40.5MB/s
[?25h Building wheel for sinfo (setup.py) ... [?25l[?25hdone
Building wheel for umap-learn (setup.py) ... [?25l[?25hdone
Building wheel for pynndescent (setup.py) ... [?25l[?25hdone
CPU times: user 164 ms, sys: 38.8 ms, total: 203 ms
Wall time: 17.1 s
Install kb-python¶
1 2 3 | |
[K |████████████████████████████████| 7.4MB 4.5MB/s
[K |████████████████████████████████| 51kB 3.5MB/s
[K |████████████████████████████████| 51.7MB 48kB/s
[K |████████████████████████████████| 20.6MB 1.5MB/s
[K |████████████████████████████████| 112kB 52.1MB/s
[K |████████████████████████████████| 9.9MB 47.1MB/s
[K |████████████████████████████████| 276kB 40.5MB/s
[?25h Installing build dependencies ... [?25l[?25hdone
Getting requirements to build wheel ... [?25l[?25hdone
Preparing wheel metadata ... [?25l[?25hdone
Building wheel for pyseq-align (PEP 517) ... [?25l[?25hdone
Building wheel for kb-python (setup.py) ... [?25l[?25hdone
Building wheel for loompy (setup.py) ... [?25l[?25hdone
Building wheel for ngs-tools (setup.py) ... [?25l[?25hdone
Building wheel for numpy-groupies (setup.py) ... [?25l[?25hdone
[31mERROR: ngs-tools 1.4.0 has requirement numba>=0.53.1, but you'll have numba 0.51.2 which is incompatible.[0m
[31mERROR: ngs-tools 1.4.0 has requirement tqdm>=4.50.0, but you'll have tqdm 4.41.1 which is incompatible.[0m
CPU times: user 570 ms, sys: 95.8 ms, total: 666 ms
Wall time: 1min 1s
Download the data¶
1 2 3 4 5 6 | |
CPU times: user 1.94 s, sys: 318 ms, total: 2.26 s
Wall time: 4min 59s
Download an index¶
This data consists of peripheral blood mononuclear cells from a human, so we download the human index.
1 | |
[2021-07-07 18:47:56,003] INFO [download] Downloading files for human from https://caltech.box.com/shared/static/v1nm7lpnqz5syh8dyzdk2zs8bglncfib.gz to tmp/v1nm7lpnqz5syh8dyzdk2zs8bglncfib.gz
100% 2.23G/2.23G [02:48<00:00, 14.2MB/s]
[2021-07-07 18:50:44,475] INFO [download] Extracting files from tmp/v1nm7lpnqz5syh8dyzdk2zs8bglncfib.gz
Pseudoalignment and counting¶
Run kallisto and bustools¶
1 2 3 4 5 6 | |
[2021-07-07 18:51:36,108] INFO [count] Using index index.idx to generate BUS file to output from
[2021-07-07 18:51:36,109] INFO [count] pbmc_1k_v3_fastqs/pbmc_1k_v3_S1_L001_R1_001.fastq.gz
[2021-07-07 18:51:36,109] INFO [count] pbmc_1k_v3_fastqs/pbmc_1k_v3_S1_L001_R2_001.fastq.gz
[2021-07-07 18:51:36,109] INFO [count] pbmc_1k_v3_fastqs/pbmc_1k_v3_S1_L002_R1_001.fastq.gz
[2021-07-07 18:51:36,109] INFO [count] pbmc_1k_v3_fastqs/pbmc_1k_v3_S1_L002_R2_001.fastq.gz
[2021-07-07 19:04:53,157] INFO [count] Sorting BUS file output/output.bus to output/tmp/output.s.bus
[2021-07-07 19:05:21,205] INFO [count] Whitelist not provided
[2021-07-07 19:05:21,205] INFO [count] Copying pre-packaged 10XV3 whitelist to output
[2021-07-07 19:05:22,196] INFO [count] Inspecting BUS file output/tmp/output.s.bus
[2021-07-07 19:05:40,875] INFO [count] Correcting BUS records in output/tmp/output.s.bus to output/tmp/output.s.c.bus with whitelist output/10x_version3_whitelist.txt
[2021-07-07 19:06:01,625] INFO [count] Sorting BUS file output/tmp/output.s.c.bus to output/output.unfiltered.bus
[2021-07-07 19:06:22,834] INFO [count] Generating count matrix output/counts_unfiltered/cells_x_genes from BUS file output/output.unfiltered.bus
[2021-07-07 19:06:38,641] INFO [count] Reading matrix output/counts_unfiltered/cells_x_genes.mtx
[2021-07-07 19:06:46,637] INFO [count] Writing matrix to h5ad output/counts_unfiltered/adata.h5ad
... storing 'gene_name' as categorical
[2021-07-07 19:06:47,631] INFO [count] Filtering with bustools
[2021-07-07 19:06:47,631] INFO [count] Generating whitelist output/filter_barcodes.txt from BUS file output/output.unfiltered.bus
[2021-07-07 19:06:47,815] INFO [count] Correcting BUS records in output/output.unfiltered.bus to output/tmp/output.unfiltered.c.bus with whitelist output/filter_barcodes.txt
[2021-07-07 19:06:56,813] INFO [count] Sorting BUS file output/tmp/output.unfiltered.c.bus to output/output.filtered.bus
[2021-07-07 19:07:13,988] INFO [count] Generating count matrix output/counts_filtered/cells_x_genes from BUS file output/output.filtered.bus
[2021-07-07 19:07:27,060] INFO [count] Reading matrix output/counts_filtered/cells_x_genes.mtx
[2021-07-07 19:07:32,997] INFO [count] Writing matrix to h5ad output/counts_filtered/adata.h5ad
... storing 'gene_name' as categorical
CPU times: user 6.71 s, sys: 889 ms, total: 7.6 s
Wall time: 16min
Basic QC¶
1 2 3 4 5 6 7 | |
1 2 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
/usr/local/lib/python3.7/dist-packages/anndata/utils.py:117: UserWarning: Suffix used (-[0-9]+) to deduplicate index values may make index values difficult to interpret. There values with a similar suffixes in the index. Consider using a different delimiter by passing `join={delimiter}`Example key collisions generated by the make_index_unique algorithm: ['SNORD116-1', 'SNORD116-2', 'SNORD116-3', 'SNORD116-4', 'SNORD116-5']
+ str(example_colliding_values)
1 | |
AnnData object with n_obs × n_vars = 259615 × 60623
var: 'gene_name', 'gene_id'
Test for library saturation¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
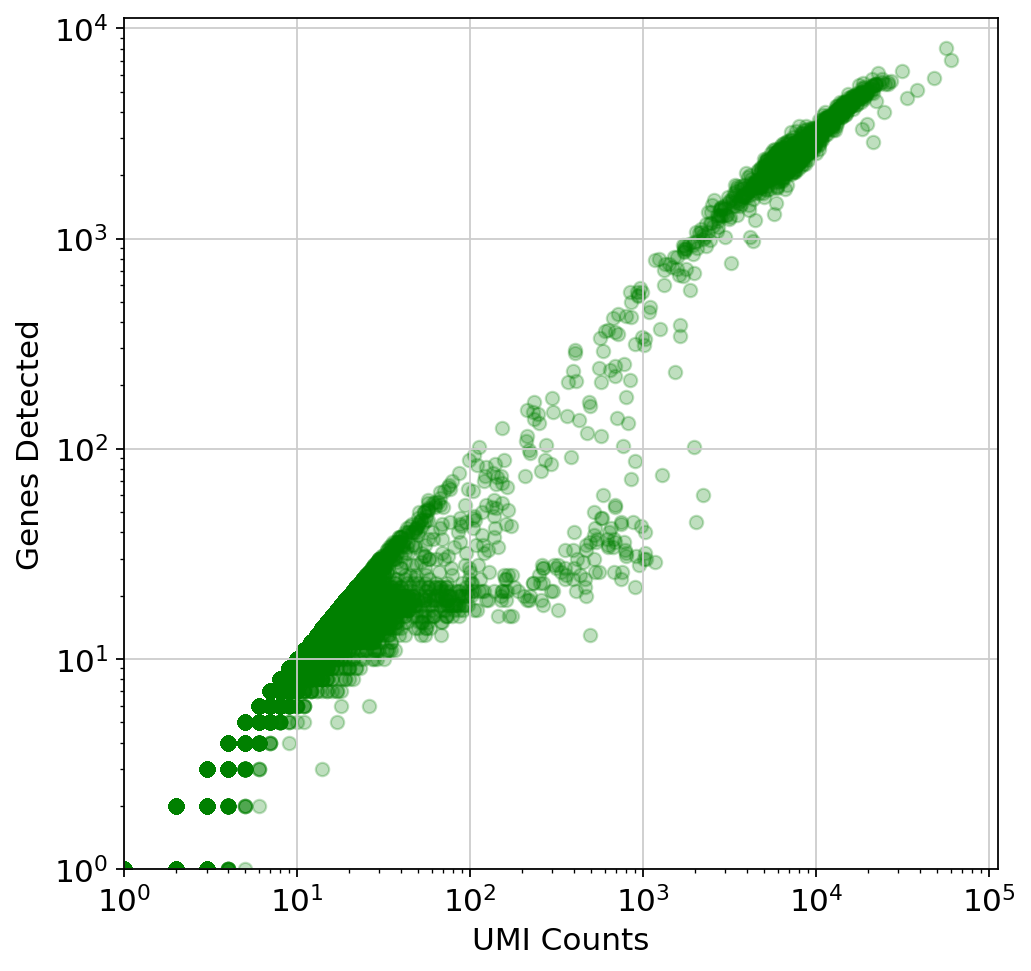
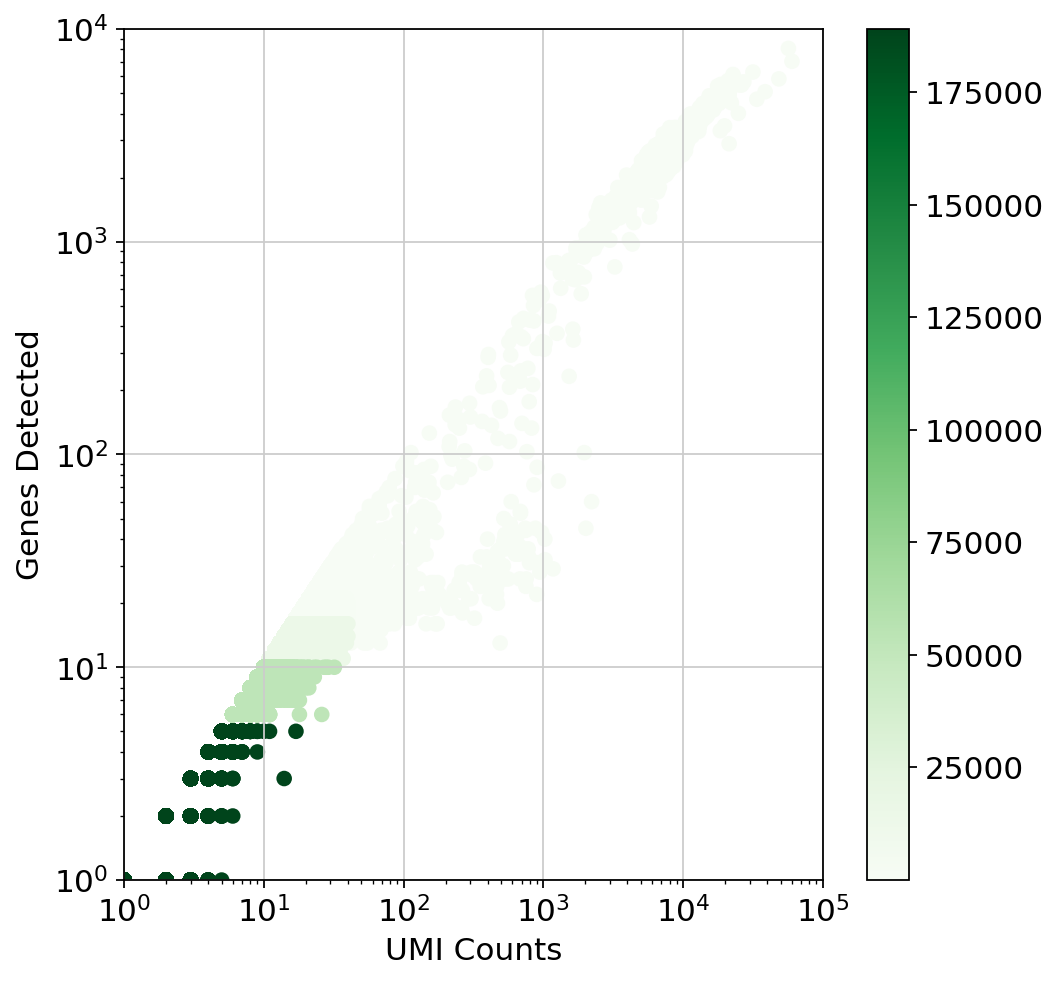
This plot is very misleading, as even the small alpha can't accurately show how many points are stacked at one location (This takes about a minute to run since there are a lot of points)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
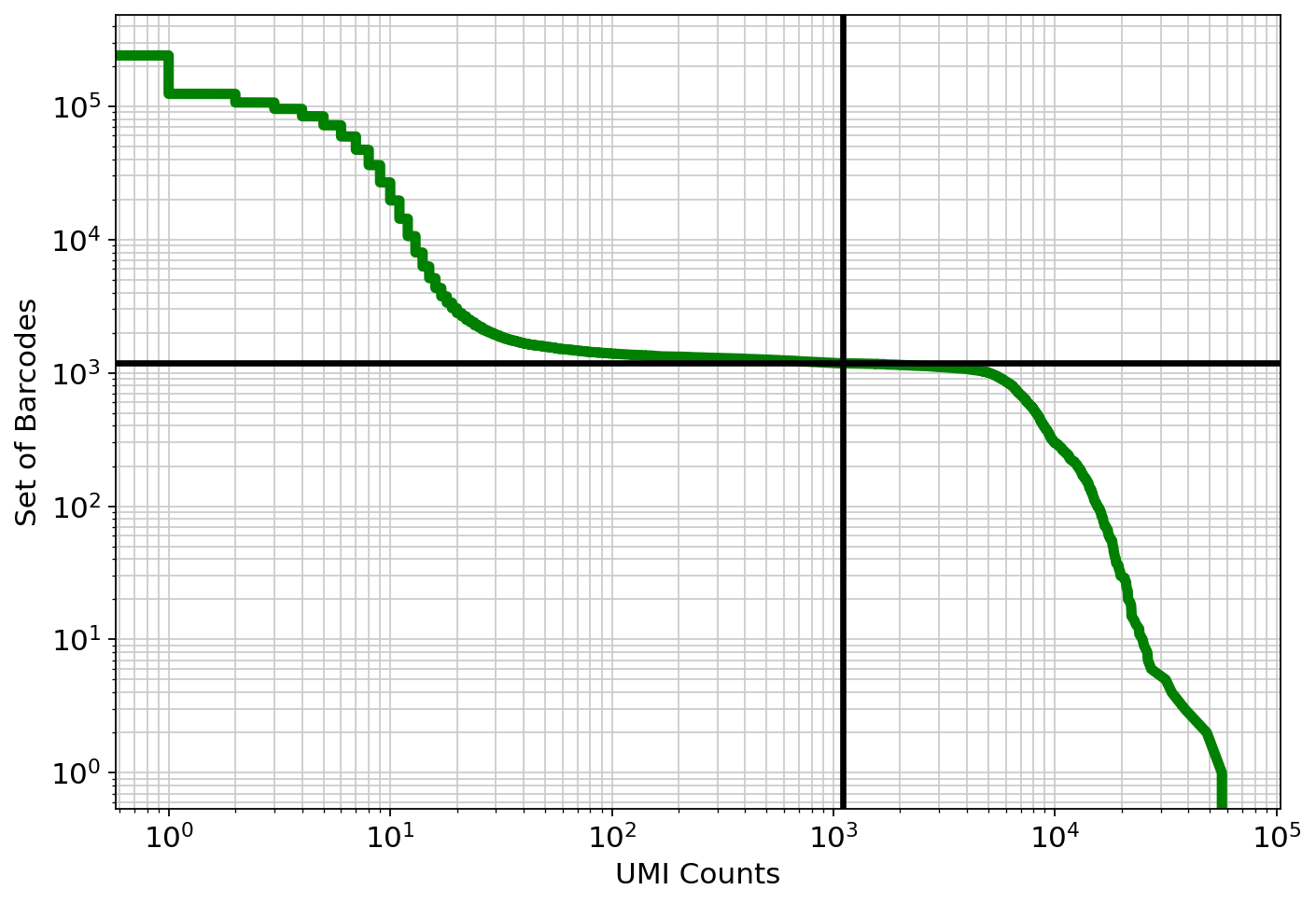
Examine the knee plot¶
The "knee plot" was introduced in the Drop-seq paper: - Macosko et al., Highly parallel genome-wide expression profiling of individual cells using nanoliter droplets, 2015. DOI:10.1016/j.cell.2015.05.002
In this plot cells are ordered by the number of UMI counts associated to them (shown on the x-axis), and the fraction of droplets with at least that number of cells is shown on the y-axis:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
Analysis¶
It is useful to examine mitochondrial genes, which are important for quality control. (Lun, McCarthy & Marioni, 2017) write that
High proportions are indicative of poor-quality cells (Islam et al. 2014; Ilicic et al. 2016), possibly because of loss of cytoplasmic RNA from perforated cells. The reasoning is that mitochondria are larger than individual transcript molecules and less likely to escape through tears in the cell membrane.
Note you can also use the function pp.calculate_qc_metrics to compute the fraction of mitochondrial genes and additional measures.
Show those genes that yield the highest fraction of counts in each single cells, across all cells.
1 | |
normalizing counts per cell
finished (0:00:00)
/usr/local/lib/python3.7/dist-packages/scanpy/preprocessing/_normalization.py:182: UserWarning: Some cells have zero counts
warn(UserWarning('Some cells have zero counts'))

Filter¶
Begin by filtering cells according to various criteria. First, a filter for genes and cells based on minimum thresholds:
1 2 3 4 5 | |
1 | |
View of AnnData object with n_obs × n_vars = 1180 × 31837
var: 'gene_name', 'gene_id'
1 2 | |
filtered out 5 cells that have less than 200 genes expressed
Trying to set attribute `.obs` of view, copying.
filtered out 5884 genes that are detected in less than 3 cells
1 | |
AnnData object with n_obs × n_vars = 1175 × 25953
obs: 'n_genes'
var: 'gene_name', 'gene_id', 'n_cells'
Next, filter by mitochondrial gene content
1 2 3 4 5 6 7 | |
Perform a QC check of the counts post-filtering
1 2 | |
... storing 'gene_name' as categorical
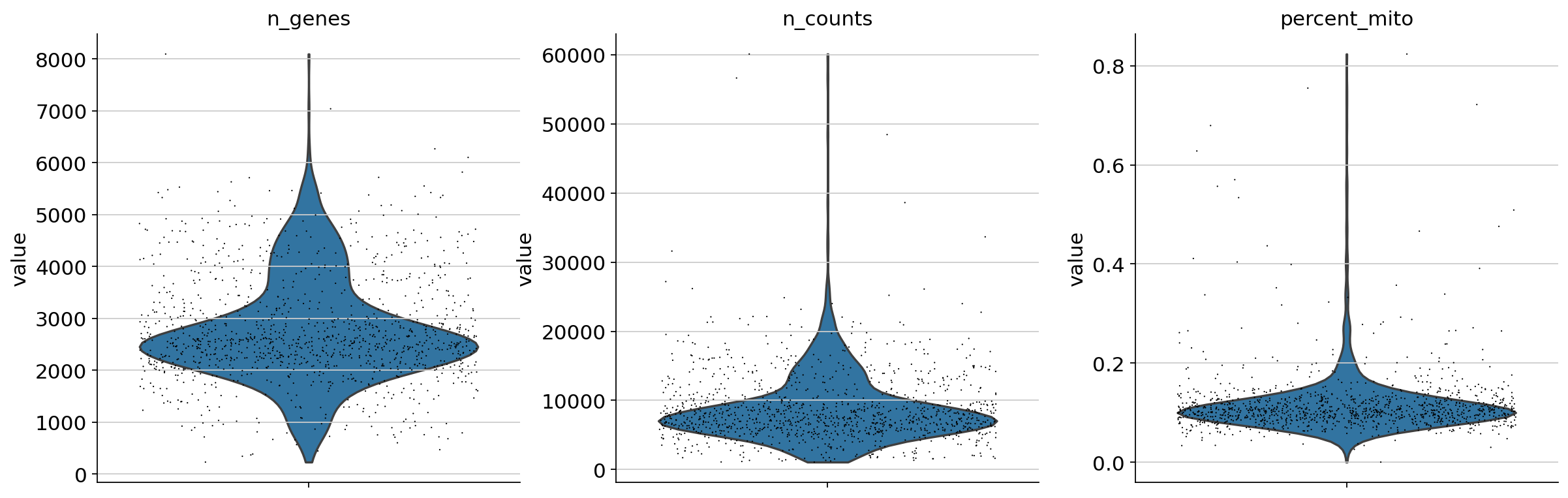
1 2 3 | |
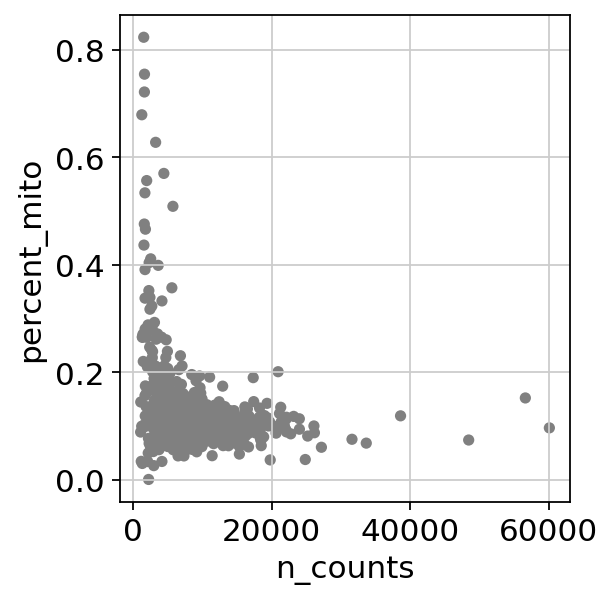
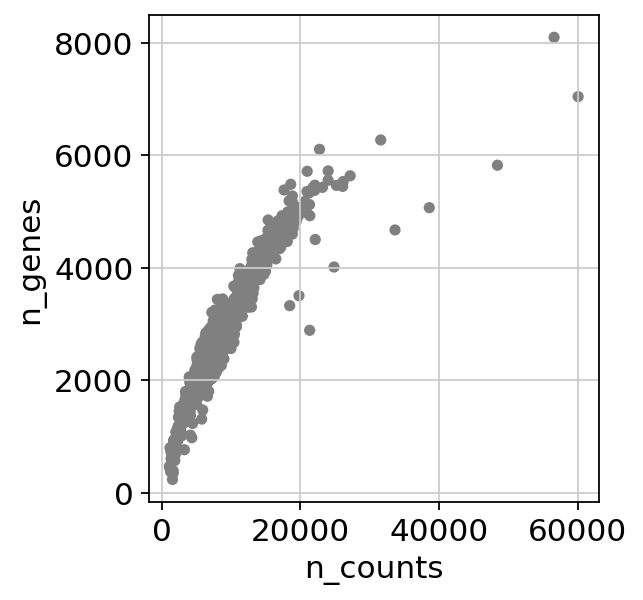
1 2 | |
1 2 | |
1 | |
View of AnnData object with n_obs × n_vars = 1175 × 25953
obs: 'n_genes', 'percent_mito', 'n_counts'
var: 'gene_name', 'gene_id', 'n_cells'
Normalize counts¶
Total-count normalize (library-size correct) the data matrix $\mathbf{X}$ to 10,000 reads per cell, so that counts become comparable among cells.
1 2 | |
normalizing counts per cell
finished (0:00:00)
/usr/local/lib/python3.7/dist-packages/scanpy/preprocessing/_normalization.py:155: UserWarning: Revieved a view of an AnnData. Making a copy.
view_to_actual(adata)
Log the counts
1 2 | |
Lets now look at the highest expressed genes after filtering, normalization, and log
1 | |
normalizing counts per cell
finished (0:00:00)
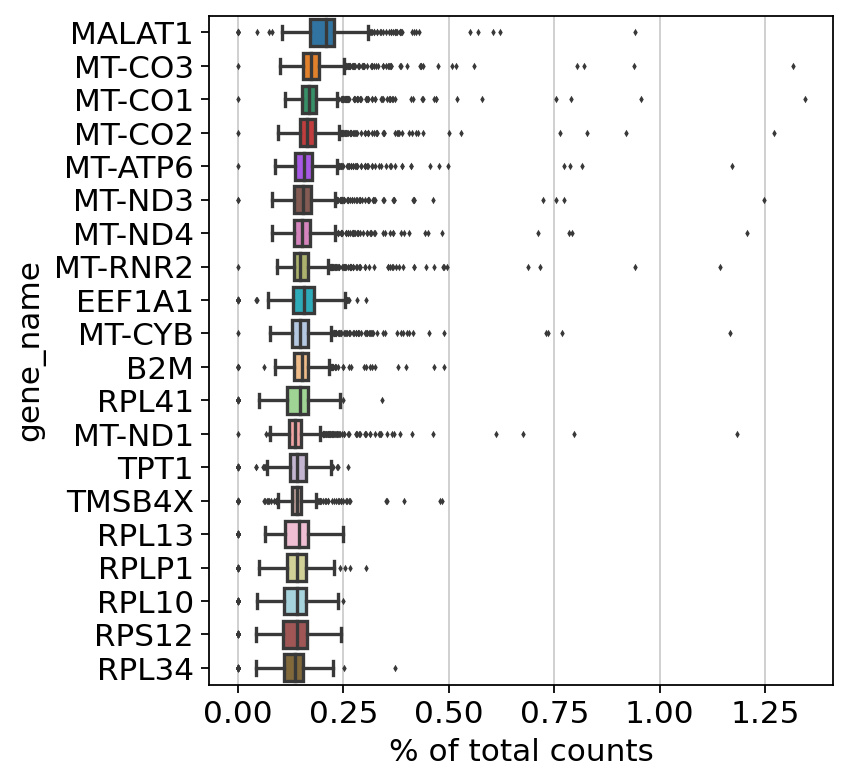
Set the .raw attribute of AnnData object to the normalized and logarithmized raw gene expression for later use in differential testing and visualizations of gene expression. This simply freezes the state of the AnnData object.
The unnormalized data is stored in .raw.
1 | |
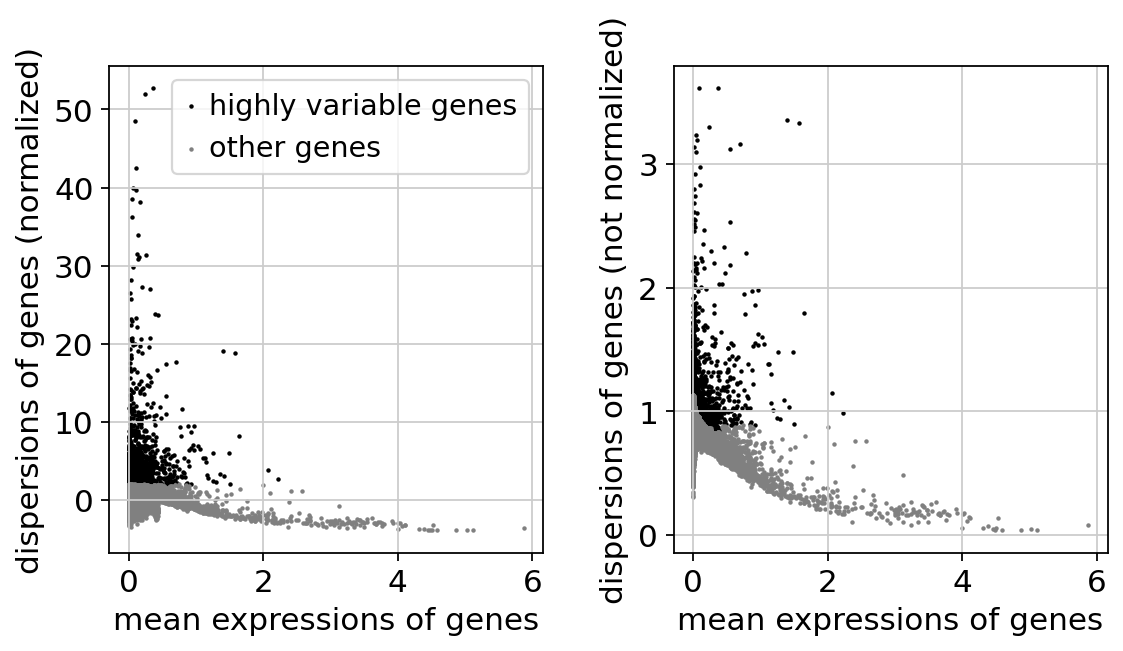
Identify highly-variable genes.¶
1 2 | |
If you pass `n_top_genes`, all cutoffs are ignored.
extracting highly variable genes
/usr/local/lib/python3.7/dist-packages/statsmodels/tools/_testing.py:19: FutureWarning: pandas.util.testing is deprecated. Use the functions in the public API at pandas.testing instead.
import pandas.util.testing as tm
finished (0:00:01)
--> added
'highly_variable', boolean vector (adata.var)
'means', float vector (adata.var)
'dispersions', float vector (adata.var)
'dispersions_norm', float vector (adata.var)
1 | |
Regress out effects of total counts per cell and the percentage of mitochondrial genes expressed. Scale the data to unit variance.
We do not regress out as per https://github.com/theislab/scanpy/issues/526
1 | |
Scaling the data¶
Scale each gene to unit variance. Clip values exceeding standard deviation 10.
1 | |
... as `zero_center=True`, sparse input is densified and may lead to large memory consumption
Principal component analysis¶
Reduce the dimensionality of the data by running principal component analysis (PCA), which reveals the main axes of variation and denoises the data.
1 2 | |
computing PCA
on highly variable genes
with n_comps=50
finished (0:00:00)
1 | |
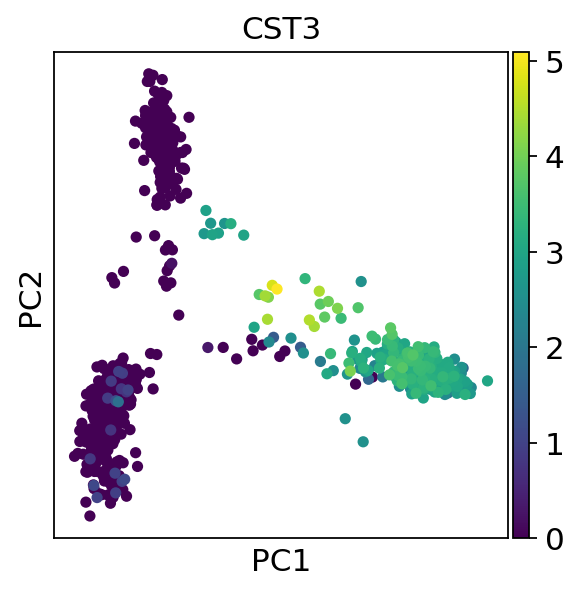
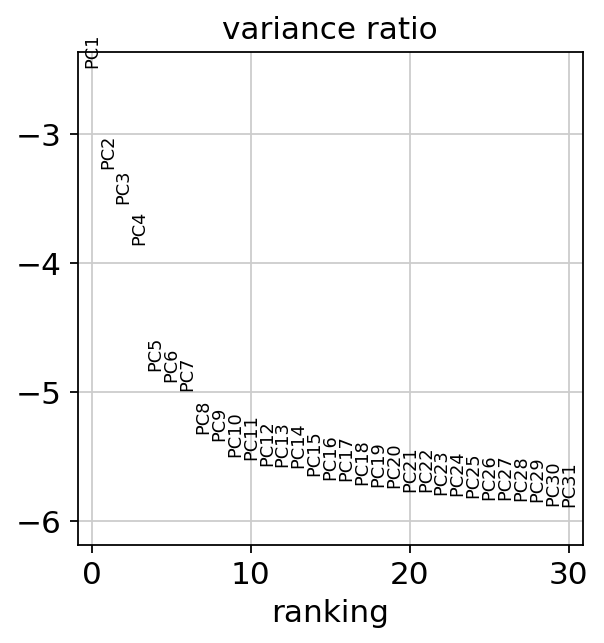
Let us inspect the contribution of single PCs to the total variance in the data. This gives us information about how many PCs we should consider in order to compute the neighborhood relations of cells, e.g. used in the clustering function sc.tl.leiden() or tSNE sc.tl.tsne(). In our experience, often, a rough estimate of the number of PCs does fine.
1 | |
1 | |
AnnData object with n_obs × n_vars = 1175 × 25953
obs: 'n_genes', 'percent_mito', 'n_counts'
var: 'gene_name', 'gene_id', 'n_cells', 'highly_variable', 'means', 'dispersions', 'dispersions_norm', 'mean', 'std'
uns: 'log1p', 'hvg', 'pca'
obsm: 'X_pca'
varm: 'PCs'
Compute the neighborhood graph¶
Next we compute the neighborhood graph of cells using the PCA representation of the data matrix. You might simply use default values here. In order to be consistent with Seurat's results, we use the following values.
1 | |
computing neighbors
using 'X_pca' with n_pcs = 10
/usr/local/lib/python3.7/dist-packages/numba/np/ufunc/parallel.py:363: NumbaWarning: The TBB threading layer requires TBB version 2019.5 or later i.e., TBB_INTERFACE_VERSION >= 11005. Found TBB_INTERFACE_VERSION = 9107. The TBB threading layer is disabled.
warnings.warn(problem)
finished: added to `.uns['neighbors']`
`.obsp['distances']`, distances for each pair of neighbors
`.obsp['connectivities']`, weighted adjacency matrix (0:00:26)
Embed the neighborhood graph¶
UMAP¶
UMAP (UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction) is a manifold learning technique that can also be used to visualize cells. It was published in:
- McInnes, Leland, John Healy, and James Melville. "Umap: Uniform manifold approximation and projection for dimension reduction." arXiv preprint arXiv:1802.03426 (2018).
We run that to visualize the results:
1 2 3 | |
1 | |
computing UMAP
finished: added
'X_umap', UMAP coordinates (adata.obsm) (0:00:04)
1 | |

Cluster the neighborhood graph¶
Clustering¶
There are many algorithms for clustering cells, and while they have been compared in detail in various benchmarks (see e.g., Duo et al. 2018), there is no univerally agreed upon method. Here we demonstrate clustering using Louvain clustering, which is a popular method for clustering single-cell RNA-seq data. The method was published in
- Blondel, Vincent D; Guillaume, Jean-Loup; Lambiotte, Renaud; Lefebvre, Etienne (9 October 2008). "Fast unfolding of communities in large networks". Journal of Statistical Mechanics: Theory and Experiment. 2008 (10): P10008.
Note that Louvain clustering directly clusters the neighborhood graph of cells, which we already computed in the previous section.
1 | |
running Louvain clustering
using the "louvain" package of Traag (2017)
finished: found 8 clusters and added
'louvain', the cluster labels (adata.obs, categorical) (0:00:00)
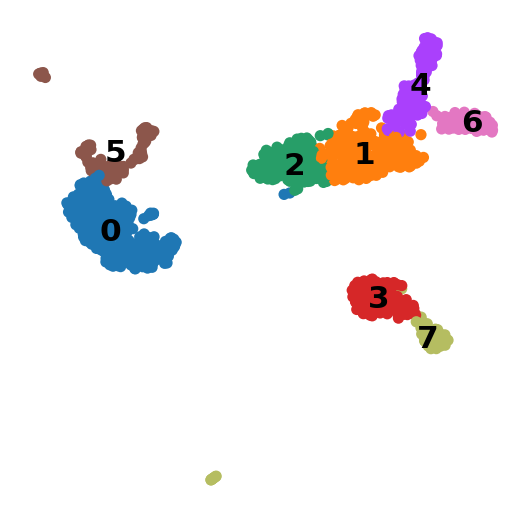
A plot of the clusters is shown below:
1 | |
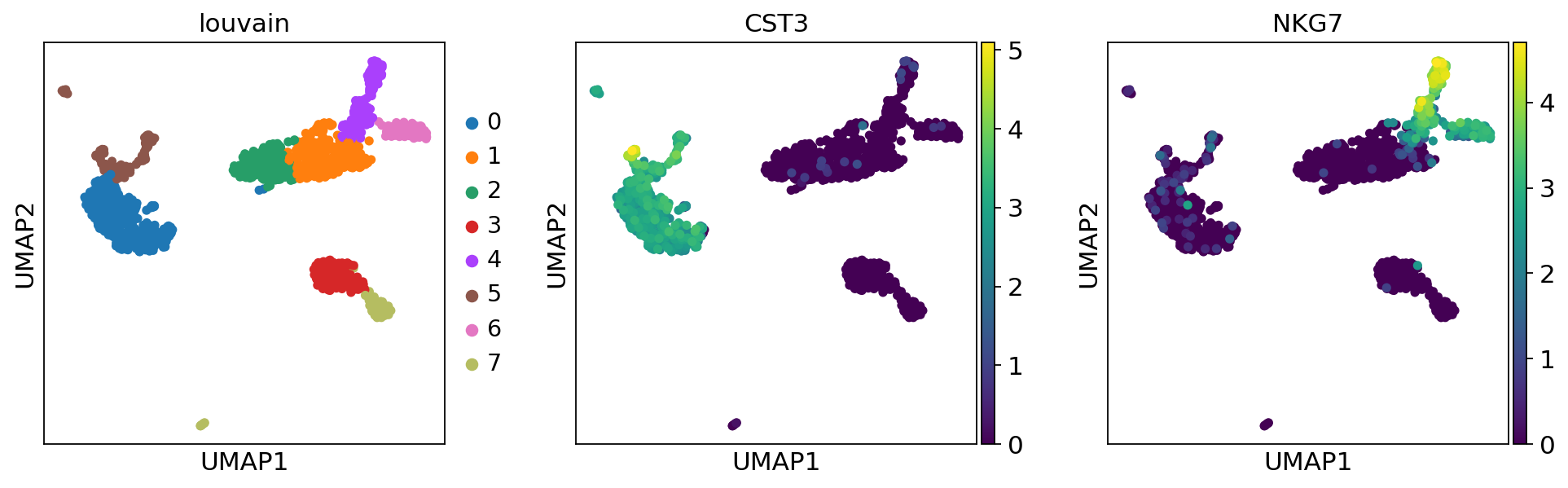
Find marker genes¶
A key aspect of annotating a cell atlas is identifying "marker genes". These are genes specific to individual clusters that "mark" them, and are important both for assigning functions to cell clusters, and for designing downstream experiments to probe activity of clusters.
A gene marker analysis begins with ranking genes in each cluster according to how different they are relative to other clusters. Typically the t-test is used for this purpose.
1 2 | |
ranking genes
finished: added to `.uns['rank_genes_groups']`
'names', sorted np.recarray to be indexed by group ids
'scores', sorted np.recarray to be indexed by group ids
'logfoldchanges', sorted np.recarray to be indexed by group ids
'pvals', sorted np.recarray to be indexed by group ids
'pvals_adj', sorted np.recarray to be indexed by group ids (0:00:00)
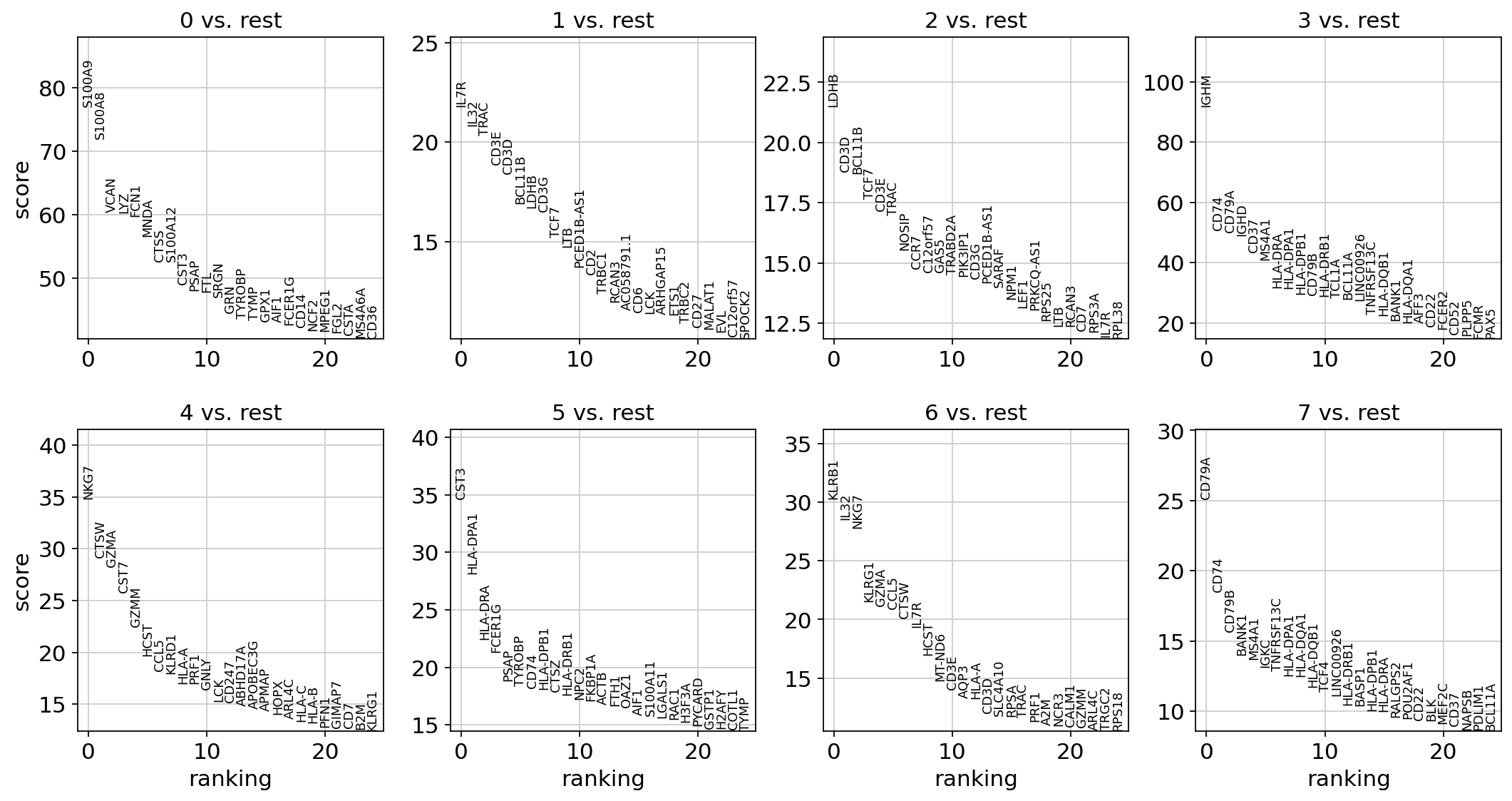
1 | |
An alternative to the parametric t-test is the non-parametric Wilcoxon rank-sum (Mann-Whitney-U) test.
1 2 | |
ranking genes
finished (0:00:03)
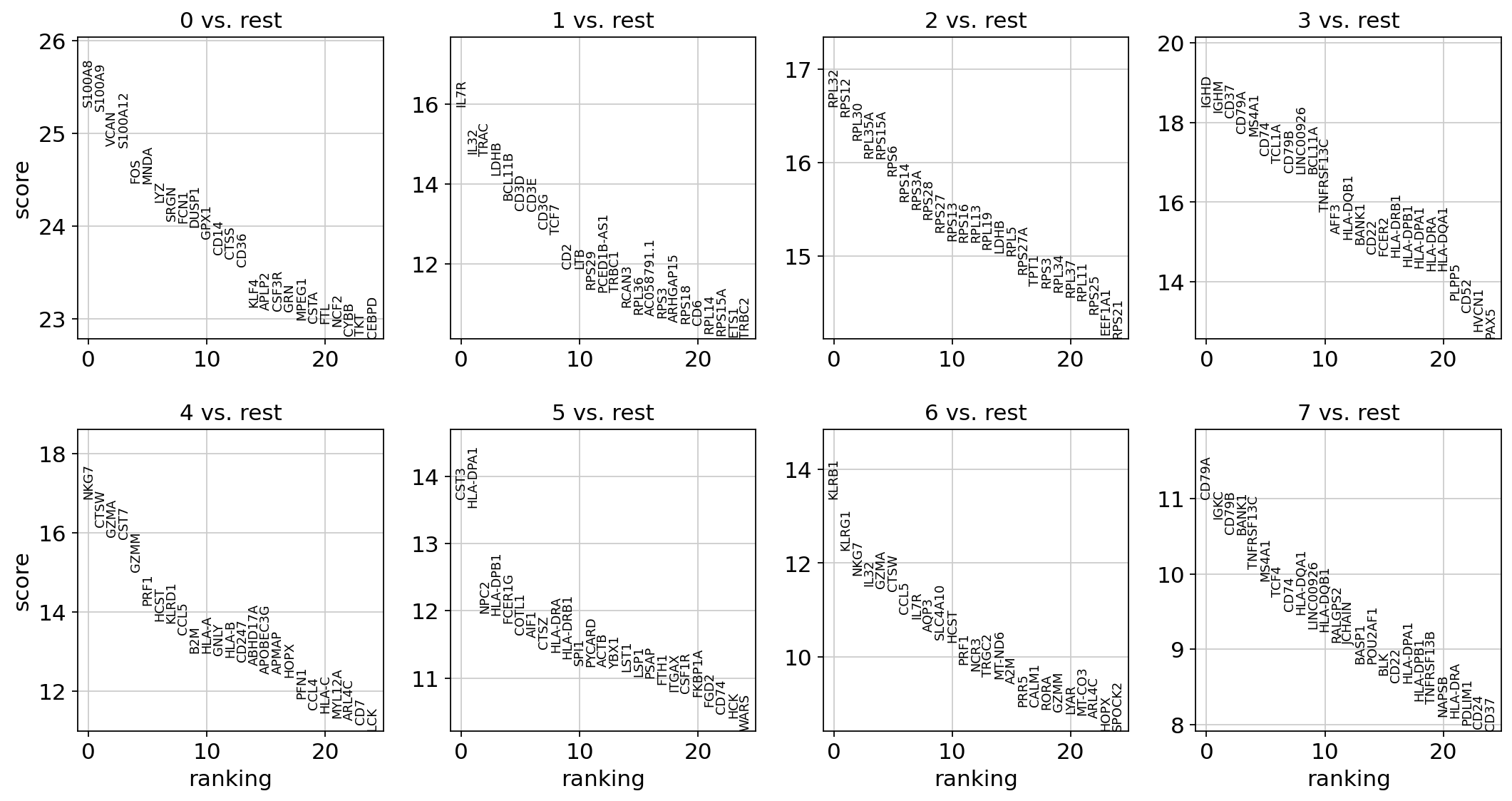
As an alternative, genes can be ranked using logistic regression (see Natranos et al. (2018)).
1 | |
1 2 | |
ranking genes
finished (0:00:18)
/usr/local/lib/python3.7/dist-packages/sklearn/linear_model/_logistic.py:940: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
extra_warning_msg=_LOGISTIC_SOLVER_CONVERGENCE_MSG)
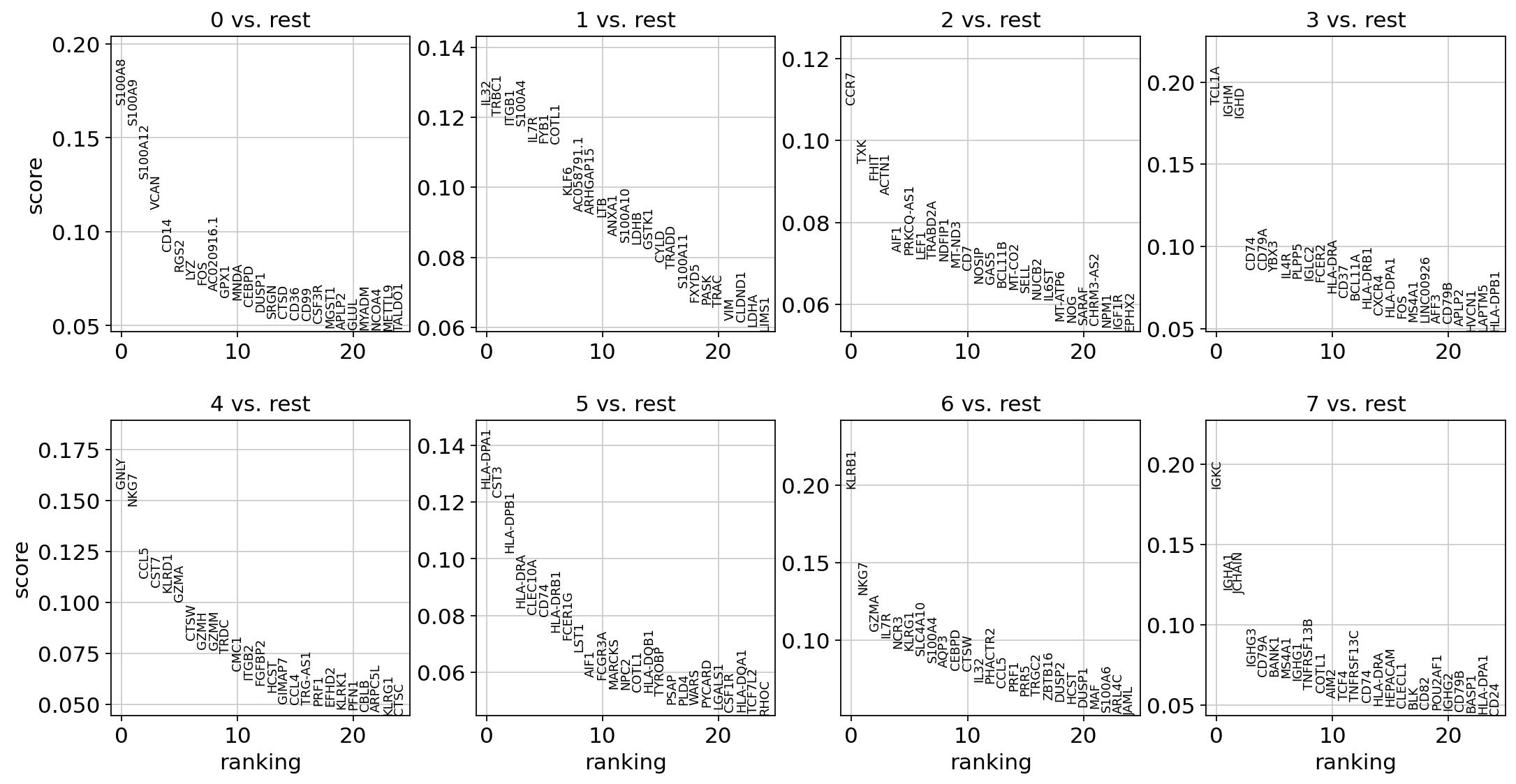
With the exceptions of IL7R, which is only found by the t-test and FCER1A, which is only found by the other two appraoches, all marker genes are recovered in all approaches.
| Louvain Group | Markers | Cell Type |
|---|---|---|
| 0 | IL7R | CD4 T cells |
| 1 | CD14, LYZ | CD14+ Monocytes |
| 2 | MS4A1 | B cells |
| 3 | GNLY, NKG7 | NK cells |
| 4 | FCGR3A, MS4A7 | FCGR3A+ Monocytes |
| 5 | CD8A | CD8 T cells |
| 6 | MS4A1 | B cells |
Let us also define a list of marker genes for later reference.
1 2 3 | |
Reload the object that has been save with the Wilcoxon Rank-Sum test result.
Show the 10 top ranked genes per cluster 0, 1, ..., 7 in a dataframe.
1 | |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|---|
| 0 | S100A8 | IL7R | RPL32 | IGHD | NKG7 | CST3 | KLRB1 | CD79A |
| 1 | S100A9 | IL32 | RPS12 | IGHM | CTSW | HLA-DPA1 | KLRG1 | IGKC |
| 2 | VCAN | TRAC | RPL30 | CD37 | GZMA | NPC2 | NKG7 | CD79B |
| 3 | S100A12 | LDHB | RPL35A | CD79A | CST7 | HLA-DPB1 | IL32 | BANK1 |
| 4 | FOS | BCL11B | RPS15A | MS4A1 | GZMM | FCER1G | GZMA | TNFRSF13C |
Get a table with the scores and groups.
1 2 3 4 5 | |
| 0_n | 0_p | 1_n | 1_p | 2_n | 2_p | 3_n | 3_p | 4_n | 4_p | 5_n | 5_p | 6_n | 6_p | 7_n | 7_p | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | S100A8 | 4.325218e-141 | IL7R | 3.851653e-57 | RPL32 | 7.151780e-62 | IGHD | 1.303809e-75 | NKG7 | 9.495682e-64 | CST3 | 1.595268e-42 | KLRB1 | 8.274802e-41 | CD79A | 3.916006e-28 |
| 1 | S100A9 | 1.357507e-140 | IL32 | 3.390931e-49 | RPS12 | 4.320062e-61 | IGHM | 1.624935e-74 | CTSW | 1.281002e-58 | HLA-DPA1 | 9.721044e-42 | KLRG1 | 1.245774e-34 | IGKC | 7.115329e-27 |
| 2 | VCAN | 1.698042e-136 | TRAC | 5.952130e-49 | RPL30 | 2.823714e-59 | CD37 | 1.704719e-73 | GZMA | 5.700633e-57 | NPC2 | 5.443673e-33 | NKG7 | 7.556990e-32 | CD79B | 6.053017e-26 |
| 3 | S100A12 | 2.736086e-136 | LDHB | 6.487053e-46 | RPL35A | 6.098855e-58 | CD79A | 2.184785e-70 | CST7 | 1.401230e-56 | HLA-DPB1 | 7.522829e-33 | IL32 | 1.135243e-30 | BANK1 | 6.905314e-26 |
| 4 | FOS | 3.264834e-132 | BCL11B | 4.040622e-42 | RPS15A | 6.949561e-58 | MS4A1 | 6.806009e-70 | GZMM | 5.222455e-51 | FCER1G | 3.106843e-32 | GZMA | 1.885113e-30 | TNFRSF13C | 7.946763e-24 |
Compare to a single cluster.
1 2 | |
ranking genes
finished (0:00:00)
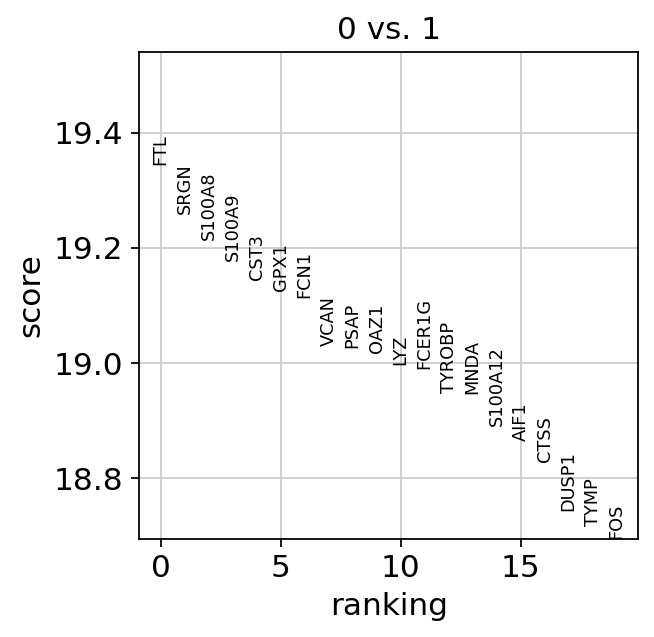
If we want a more detailed view for a certain group, use sc.pl.rank_genes_groups_violin.
1 | |
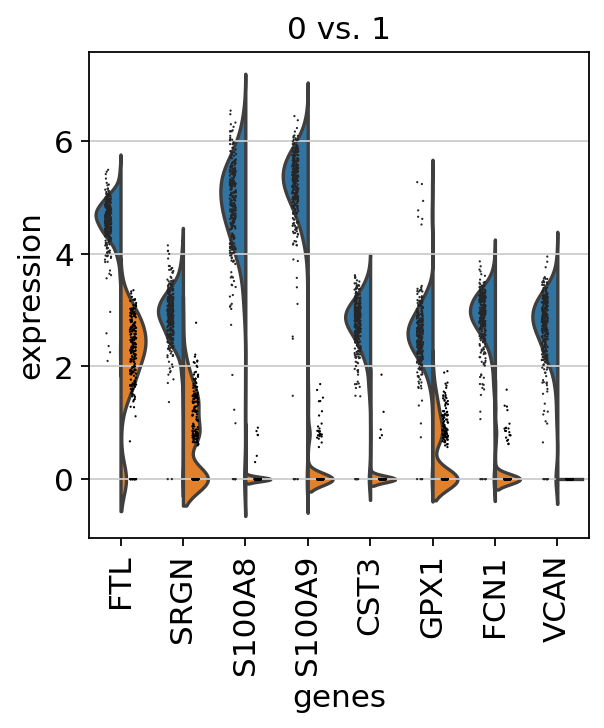
If you want to compare a certain gene across groups, use the following.
1 | |

Actually mark the cell types.
1 | |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|---|
| 0 | S100A8 | IL7R | RPL32 | IGHD | NKG7 | CST3 | KLRB1 | CD79A |
| 1 | S100A9 | IL32 | RPS12 | IGHM | CTSW | HLA-DPA1 | KLRG1 | IGKC |
| 2 | VCAN | TRAC | RPL30 | CD37 | GZMA | NPC2 | NKG7 | CD79B |
| 3 | S100A12 | LDHB | RPL35A | CD79A | CST7 | HLA-DPB1 | IL32 | BANK1 |
| 4 | FOS | BCL11B | RPS15A | MS4A1 | GZMM | FCER1G | GZMA | TNFRSF13C |
| 5 | MNDA | CD3D | RPS6 | CD74 | PRF1 | COTL1 | CTSW | MS4A1 |
| 6 | LYZ | CD3E | RPS14 | TCL1A | HCST | AIF1 | CCL5 | TCF4 |
| 7 | SRGN | CD3G | RPS3A | CD79B | KLRD1 | CTSZ | IL7R | CD74 |
| 8 | FCN1 | TCF7 | RPS28 | LINC00926 | CCL5 | HLA-DRA | AQP3 | HLA-DQA1 |
| 9 | DUSP1 | CD2 | RPS27 | BCL11A | B2M | HLA-DRB1 | SLC4A10 | LINC00926 |
Recall
| Louvain Group | Markers | Cell Type |
|---|---|---|
| 0 | IL7R | CD4 T cells |
| 1 | CD14, LYZ | CD14+ Monocytes |
| 2 | MS4A1 | B cells |
| 3 | GNLY, NKG7 | NK cells |
| 4 | FCGR3A, MS4A7 | FCGR3A+ Monocytes |
| 5 | CD8A | CD8 T cells |
| 6 | MS4A1 | B cells |
1 2 3 4 5 6 7 8 9 10 11 | |
1 2 | |
1 | |
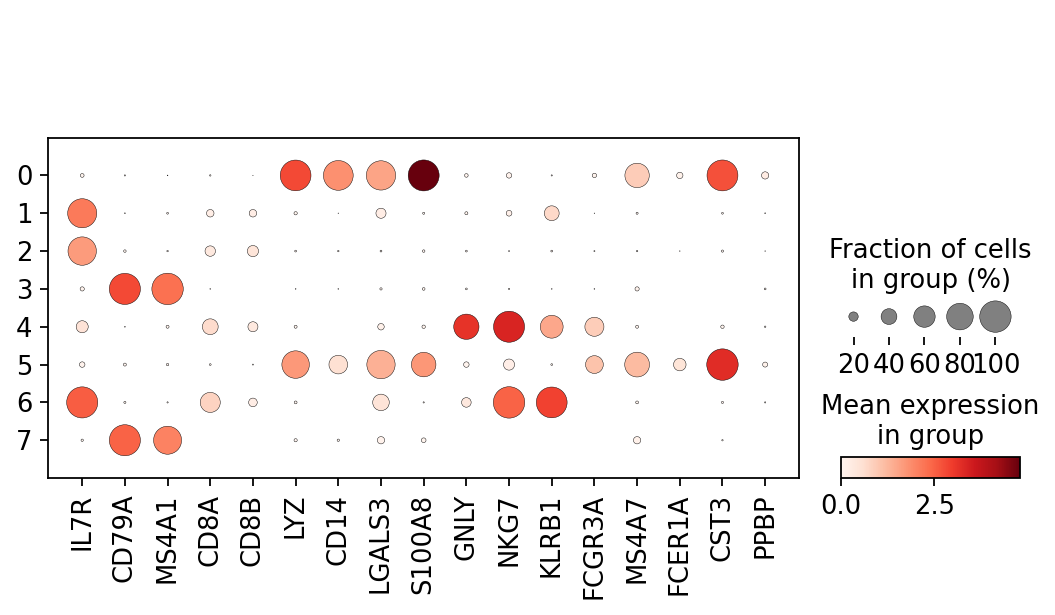
Now that we annotated the cell types, let us visualize the marker genes.
1 | |
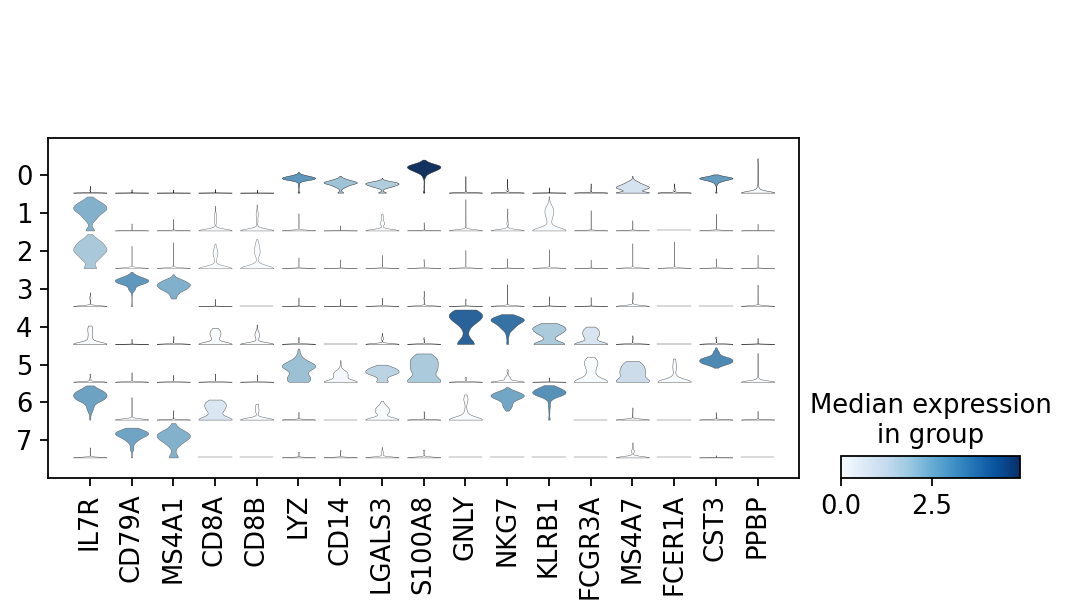
There is also a very compact violin plot.
1 | |
Note that as a result of the analysis the adata object has accumulated several annotations:
1 | |
AnnData object with n_obs × n_vars = 1175 × 25953
obs: 'n_genes', 'percent_mito', 'n_counts', 'louvain'
var: 'gene_name', 'gene_id', 'n_cells', 'highly_variable', 'means', 'dispersions', 'dispersions_norm', 'mean', 'std'
uns: 'log1p', 'hvg', 'pca', 'neighbors', 'umap', 'louvain', 'louvain_colors', 'rank_genes_groups'
obsm: 'X_pca', 'X_umap'
varm: 'PCs'
obsp: 'distances', 'connectivities'
If you want to export to "csv", you have the following options:
1 2 3 4 5 6 7 8 9 10 11 | |
1 2 | |
27.63 minutes
Feedback: please report any issues, or submit pull requests for improvements, in the Github repository where this notebook is located.
1 | |